
How multilingual terminology databases differ from translation memory.
Translation Memory and Multilingual Terminology Management: Same Genus, Two Different Species
“What is the difference between source terminology management and translation memory?”
I am asked this question frequently by people who aren’t translation industry professionals.
The answer is, “None, but a lot!”
In this post, I demystify the differences between terminology management and translation memory.
Comparing the Two
Let’s start by comparing the two with terminology management systems.
Source Terminology Management
Source terms are usually stored in a database of some sort. This database could be rudimentary, such as Excel, or sophisticated, such as the Acrolinx terminology manager. Terms are usually single words or very short phrases.
Along with the terms themselves, there are usually metadata of various kinds. One frequent type of metadata is term status. In the Acrolinx world, a term may be preferred, meaning that its usage is desirable, or deprecated, meaning that usage is undesirable. Other terminology databases may label undesirable terms as “forbidden” or “do not use.”
Then, there are terms whose usage is desirable in some contexts, but undesirable in others. These flexible terms are called admitted terms in Acrolinx. When we store an admitted term in the Acrolinx terminology database, we can add more metadata in the form of a note. The note can explain why the term is either preferred or deprecated, depending on its function in the sentence.
There are many other types of metadata that can be stored with terms. These data points can be anything that is salient. Examples include term origin, part-of-speech, definition information, enforcement of title case, relationship to other terms, or just about anything else under the sun.
Sophisticated source terminology databases are usually capable of storing translations. This capability is where the similarity to translation memory begins. Translated terms are linked to the source-language originals. Like their source-language brethren, translated terms are single words or short phrases.
The same metadata capabilities apply to translations of terms, because the translations are terms just like their source equivalents. Sometimes, when there are two or more translations for a source term, the preferred vs. deprecated status is particularly useful. But other metadata can be useful, as well.
Examples are the origin of the translation, or a note explaining why one translation is preferred and another isn’t. When terminology preferences are subject to negotiation between a client and a translation service provider, the metadata field “confirmed by” is very useful. In this case, the service provider has objective proof of client approval of a given term if it becomes contentious after-the-fact.
Translation Memory
In the sense of providing content that is available for reuse, translation memory (“TM”) is analogous to multilingual terminology management. TM is also a database, albeit of equivalent source- and target-language segments. The combination of a source segment and its corresponding target segment is called a translation unit (“TU”). The term translation unit is generally spoken of in the context of TM. In theory, it also applies to source-target term pairs in a terminology database.
Segments are usually sentences, and punctuation usually delimits them. But a segment could consist of more than, or less than, one full sentence, depending on many factors. For example, sometimes a complex source-language sentence is stylistically better in the target language when written as two sentences. In this case, you have a 1:2 segment relationship that is still a TU in the TM. The same could be true the other way around, but it is usually source content authors who write overly long or overly complex sentences.
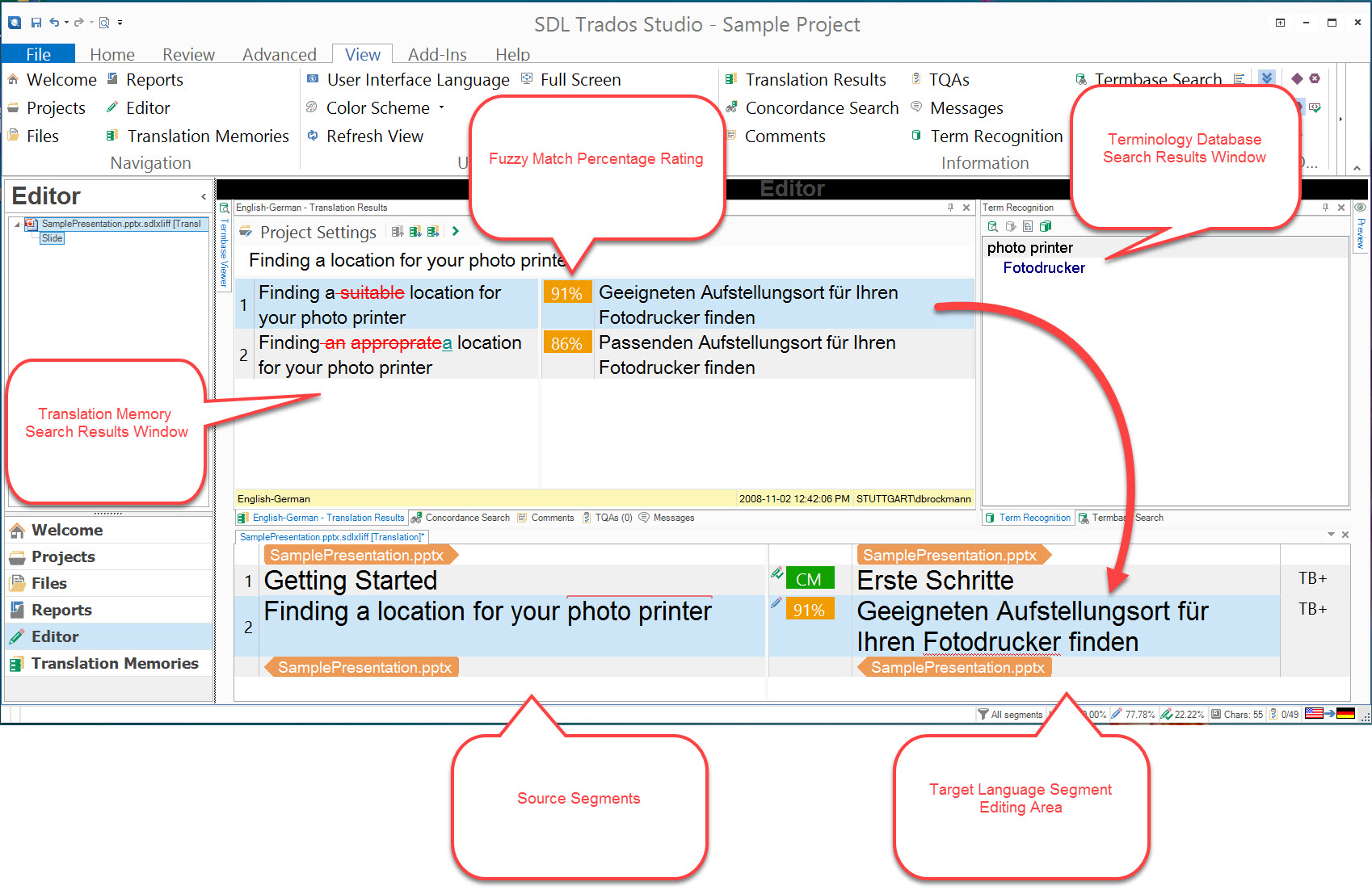
Translation editing environments use matching algorithms to traverse TM and terminology databases. These algorithms search for source-language segments and terms that match segments in the document being translated. When a match is found, the corresponding target-language segment or term is offered to the translator. Matches from TM don’t have to be exact. The algorithms account for fuzziness, and the degree of matching is reported to the translator along with the candidate translated segment.
For terms, matching must be exact in most cases, although some terminology systems, such as Acrolinx, deal well with inflections. Acrolinx is not a translation editing environment, but it does support multilingual terminology management. Acrolinx can also import and export files used by translation editing products. There are connectors available to other linguistic tools.
For example, one useful connector links Acrolinx with a visual localization product called SDL Passolo, which is used for translating software user interfaces. This connection is important because, in software localization, the user interface forms the terminological heart for translation of all other associated product documentation types.
When a source document is loaded into a translation editing environment, the software performs a segmentation process that chops up the source into a list of contiguous segments. These segments are usually presented to the translator in the format of a columnar grid. There’s a secondary column of cells that serve as editing areas into which each segment translation is written. Full and fuzzy matches are presented to the translator in another window, and there’s usually yet another window with terminology candidates. Relevant metadata may be presented in other windows.

If a translated term or segment is a good match, the translator can choose to have the translation editing software insert the translation into the target editing area. If it’s a fuzzy match, then the translator edits the segment so that it becomes an accurate representation of the source segment. The new TU is confirmed and sent back into the translation memory for future use.
Difference Between TM and Terminology
There’s a prominent difference between TM and terminology in translation editing environments. The better editing environments feature a sophisticated terminology component that tells translators if they use an unwanted term, in addition to suggesting the preferred variant. Translation memory typically makes suggestions only.
The TM suggestions may be full or fuzzy matches, and are sorted by degree of matching. However, translation memory technology doesn’t alert a translator if they have written something that is completely wrong. Terminology management systems can create such alerts, assuming the deprecated term is also in the terminology database.
Many sophisticated translation editing environments extend their searches beyond proprietary translation memories to poll other sources for potential matches. There are numerous publicly-searchable translation memories and terminology databases. Also, in more recent years, translation editing environments have been able to interact with publicly-available machine translation engines. In some cases, your results will be greatly enhanced by referencing domain-specific sources. Domain-targeted searching is one way in which terminology management and translation memory management have moved closer together.
The Grey Zone
There will always be a grey zone and usage differences between terminology management and translation memory. To be academic, a phrase represents a singular conceptual unit. As such, it is more akin to a term than to a sentence. Sentences usually contain subjects, verbs, and other parts of speech, and are separated from one another by punctuation. Phrases and terms are usually parts of sentences, separated by white space.
Why, then, doesn’t translation memory contain lots and lots of phrases, just like a large termbase made up of single and multi-word terms? The problem lies in in-context assembly and the fact that many words, and even phrases, can have multiple meanings.
At some point , the burden of assembly of phrases to create a complete sentence becomes greater than wholesale editing of a fuzzily-matched sentence. At this crossover point, TM is more useful than terminology.
A pragmatic difference between terminology management and translation memory remains. Although the purposes overlap, each has its individual advantage and is valuable in its own right.







